Codes alphanumériques
Les codes alphanumériques sont également appelés codes de caractères.
Ce sont des codes binaires pour représenter des données non numériques, telles que des alphabets (A-Z, a-z), des caractères spéciaux (*,+, /, etc.), des signes de ponctuation ainsi que des données numériques, c'est-à-dire des nombres (0-9).
Ainsi les codes alphanumériques représentent divers caractères et fonctions que l'on retrouve sur un clavier d'ordinateur.
Les différents codes alphanumériques sont :
ASCII EBCDIC
Unicode Hollerith
Discutons de chacun d’eux un par un.
Code ASCII
ASCII signifie America Standard Code for Information Interchange.
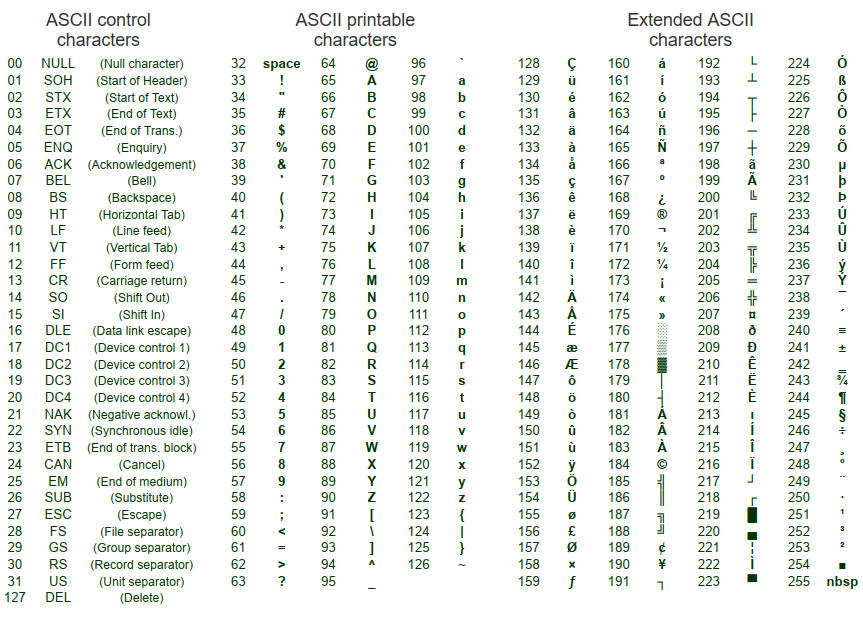
C'est un code de 7 bits, il y a donc 27 = 128 codes de 0000000 à 1111111.
Ces 27 = 128 codes sont utilisés pour représenter divers symboles alphanumériques sur les claviers. Il est également appelé code ASCII-7.
Le tableau ci-dessous représente la valeur ASCII pour les 27 = 128 codes.
Le tableau comprend 95 caractères imprimables - 26 alphabets majuscules (A - Z), 26 alphabets minuscules (a - z), 10 chiffres (0-9), 33 caractères spéciaux (comme les signes de ponctuation, les espaces, etc.).
Outre ces 95 caractères imprimables, la table ASCII comprend également 33 caractères non imprimables, principalement des caractères de contrôle comme le retour chariot, le saut de ligne, etc.
Outre l'ASCII-7, l'ASCII-8 est également développé, ce qui représente 28 = 256 codes.
Tableau des codes ASCII pour 28 = 256 codes
Code EBCDIC
EBCDIC signifie Code d'échange décimal codé binaire étendu.
C'est un autre code alphanumérique. Il s'agit d'un codage de caractères 8 bits, développé par IBM (International Business Machines) pour étendre le Binary Coded Decimal (BCD) existant.
Tous les mainframes, périphériques et systèmes d'exploitation IBM utilisent le code EBCDIC.
Mais AIX (Advanced Interactive eXecutivde) fonctionnant sur RS/6000 et ses descendants, les systèmes IBM, Linux fonctionnant sur la série Z.
Et les systèmes d'exploitation fonctionnant sur IBM PC et ses descendants utilisent l'ASCII pour les logiciels et autres périphériques matériels pour traduire vers et depuis les encodages (ASCII vers EBCDIC et vice versa).
Il y a au total 28 = 256 codes dans EBCDIC.
Le code EBCDIC présente l'avantage de fournir une détection d'erreurs en plus des codes de parité. EBCDIC fournit également certaines fonctions de contrôle.
Dans le code EBCDIC, les 4 premiers bits sont appelés bits de zone et les 4 bits restants sont des valeurs numériques.
EBCDIC peut représenter tous les alphabets (A-Z, a-z), les chiffres (0-9), les signes de ponctuation et autres caractères spéciaux ainsi qu'un grand nombre de caractères de contrôle.
UNICODE
Unicode est un système international de codage de caractères conçu pour prendre en charge l'échange de textes (données texte) écrits dans n'importe quelle langue ancienne, écrits dans une langue différente et écrits dans une langue avec différents alphabets et symboles comme le chinois, le grec, le russe, le tibétain, etc.
Unicode contient 110 000 caractères et Unicode couvre donc près de 100 scripts.
Unicode peut être implémenté en utilisant différents codages de caractères, dont les plus courants sont UTF-16 (16-bit Unicode Transformation Format) et UTF-8.
Unicode représente les caractères en 0 et en 1 sur un ordinateur, quelle que soit la langue et la plate-forme informatique utilisées.
Il utilise 1 à 4 octets, soit 8 à 32 bits par caractère, ce qui est suffisant pour représenter tous les caractères standards des différentes langues du monde.
Le plus grand avantage d'Unicode est son utilisation mondiale avec une circonscription et des résultats sans ambigüité.
Hollerith
Le code Hollerith est un système de codage permettant de coder des données sur des cartes perforées. Le code Hollerith a été développé par Herman Hollerith en 1889.
Dans le système de codage Hollerith, il existe des cartes perforées dans lesquelles chaque ligne horizontale a une valeur différente et chaque colonne verticale correspond à des lettres (alphabets), des chiffres et des caractères spéciaux.
Le code est stocké sous forme de trous percés à des intervalles spécifiés dans la combinaison de lignes et de colonnes requise.
Bien que le code Hollerith ne soit pas largement utilisé, il est toujours utilisé dans les enregistrements sur microfilms pour stocker les données des microfilms.

![]()